최근 기술의 급격한 발전은 특히 인공지능 분야에서 두드러지며, 그 중심에는 대규모 언어 모델(LLM)이 자리잡고 있습니다. 특히, LLM은 커머스, 과학, 금융 등 광범위한 산업 분야에서 관심을 가지고 있으며, OpenAI, AI21, CoHere와 같은 주요 기업들에 의해 적극적으로 활용되고 있습니다. 특히 GPT-4와 같은 모델은 질문과 답변 작업에서 비약적인 성능 향상을 이뤄내며 기업들의 주목을 받고 있죠.
그러나 이러한 고성능 LLM을 사용하는 데에는 여러가지 단점들이 존재합니다.
비용의 부담
고성능 LLM을 사용하는 데에는 상당한 비용이 수반됩니다. 예를 들어, ChatGPT의 운영 비용은 하루에 약 70만 달러로 추정되며, 소규모 기업에서는 시스템을 운영하기 위해 매달 21,000달러 이상의 비용을 지출해야 할 수도 있습니다. 이와 같은 높은 비용은 많은 기업들에게 큰 부담이 되고 있습니다.
환경적 영향
뿐만 아니라, 대규모 LLM의 운영은 환경과 에너지 자원에도 큰 영향을 미칩니다. 환경과 에너지 자원은 단순히 경제적인 문제뿐만 아니라, 현재와 미래 세대의 사회적 복지에도 영향을 줄 수 있는 중대한 이슈입니다. 따라서 해당 기술의 사용은 매우 신중하게 접근되어야 합니다.
이러한 문제를 해결하기 위해 해당 논문에서는 FrugalGPT 접근방식을 제안하는데요.
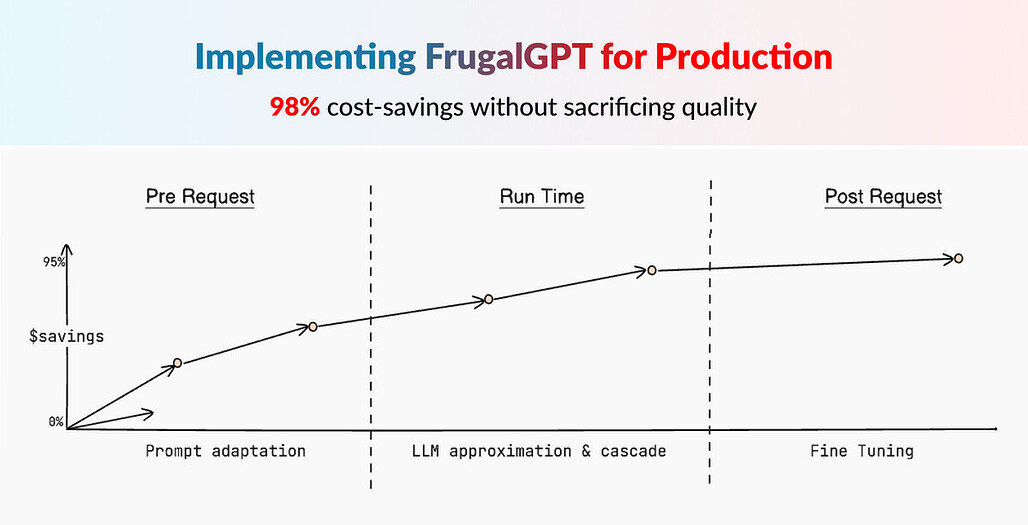
FrugalGPT 접근 방식
크게 3가지 접근 방식을 제안합니다.

Prompt adaptation
- Prompt adaptation: 인공지능 시스템에 질문을 할 때 사용하는 "프롬프트"의 크기를 줄여 비용을 절감하는 전략. LLM (Large Language Model) 질의 비용은 주로 사용하는 프롬프트의 길이에 비례하기 때문에, 프롬프트 크기를 줄이면 비용도 줄어듭니다.
▷Prompt adaptation 없이 질문하기:
"파리에는 어떤 유명한 관광지가 있나요? 에펠탑 외에 다른 장소도 궁금합니다. 가능하다면 각 장소의 역사적 중요성과 관광 정보, 방문 최적 시기, 입장료에 대해서도 알려주세요."
▷ Prompt adaptation을 사용한 질문:
"파리의 주요 관광지는 무엇입니까?"
한계점과 해결책
- 질문을 구성할 때, 기본적인 정보를 포함시키되, 필요한 경우 추가적인 세부 사항을 묻는 후속 질문을 준비합니다. 이렇게 하면 초기 비용은 낮게 유지하면서도 필요한 정보를 얻을 수 있습니다.
- 예: "파리의 주요 관광지는 무엇입니까?"라는 질문에 대한 답변을 받고, 추가적으로 관심 있는 관광지에 대해 더 구체적인 질문을 할 수 있습니다.


LLM approximation
- LLM approximation: 고가의 LLM API를 사용하는 대신, 보다 저렴한 모델이나 인프라를 활용하여 유사한 기능을 수행하는 전략.비용을 절감하면서도 필요한 작업을 효율적으로 완수할 수 있도록 돕습니다.
- LLM 근사화에서는 완료 캐시를 활용하여 한 번 처리한 질의의 응답을 저장합니다. 이후 같은 또는 유사한 질의가 들어오면, 저장된 응답을 재사용하여 빠르고 비용 효율적으로 결과를 제공합니다.
▷ 예를 들어, Cache DB를 구축해놓는 형태: 사용자가 같은 질의를 하면, 시스템은 캐시를 확인하여 즉시 저장된 응답을 제공. 새로운 LLM API 호출이 필요 없게 되므로 비용과 시간을 절약할 수 있게 됨.
한계점과 해결책
- 한계점은 캐시된 데이터가 항상 최신 상태인지 확인하는 것입니다. 예를 들어, 특정 데이터(실시간 데이터)가 변경된 경우 캐시된 응답은 더 이상 정확하지 않을 수 있습니다.
- 해결책으로는 정기적으로 캐시를 업데이트하거나, 사용자로부터 특정 정보의 시간 민감성을 확인하는 질의를 받았을 때 캐시 대신 실시간 데이터를 제공하는 것입니다.

LLM cascade
- LLM cascade: 다양한 LLM API를 효율적으로 활용하여 비용을 절감하고 성능을 최적화하는 전략. 해당 방법은 다수의 LLM API를 순차적으로 활용하여, 최적의 응답을 찾아내는 과정을 포함합니다.
- 질의를 가장 저렴하거나 빠른 LLM API부터 시작하여 응답을 요청합니다.
- 첫 번째 LLM API의 응답이 신뢰할 수 있고 정확하다면, 그 응답을 사용하고 프로세스를 종료합니다.
- 만약 첫 번째 응답이 만족스럽지 않다면, 다음 LLM API로 넘어가 더 나은 응답을 요청합니다. 이 과정은 충분히 신뢰할 수 있는 응답을 얻을 때까지 계속됩니다.
▷ 첫 번째 친구에게 추천을 요청합니다. 이 친구는 일반적으로 맛에 대한 좋은 취향을 가지고 있지만, 오늘은 좀 확신이 없어 보입니다.
▷ 그 응답이 충분히 만족스럽지 않다면, 다음 친구에게 물어봅니다. 이 친구는 특정 요리에 대해 전문적인 지식을 가지고 있습니다.
▷ 만약 두 번째 친구의 추천도 확신이 없다면, 세 번째 친구에게 물어볼 수 있습니다. 이렇게 순차적으로 의견을 구하여 가장 신뢰할 수 있는 추천을 얻게 됩니다.
한계점과 해결책:
- 한계점은 각 단계에서 어떤 LLM API를 사용할지 결정하는 것입니다. 각 API는 성능과 비용 면에서 다를 수 있기 때문에, 최적의 순서를 결정하는 것이 중요합니다.
- 해결책으로는 성능 점수나 비용을 기반으로 LLM API를 사전에 평가하고 순서를 정하는 것입니다. 이를 통해 각 질의에 대해 가장 비용 효율적이고 정확한 응답을 빠르게 제공할 수 있습니다.



FrugalGPT의 LLM API 캐스케이드를 적용한 전략은 각각의 강점을 효과적으로 활용하여 성능을 향상시키고 비용을 절감합니다. 도구가 각 단계에서 가장 비용 효율적인 API를 선택함으로써 다양한 쿼리에 적응하는 능력은 효율성을 극대화할 뿐만 아니라 에너지 소비와 탄소 배출을 줄이는 보다 지속 가능한 AI 실천을 지원
'AI' 카테고리의 다른 글
| 생성형 AI로 AI 인플루언서 만드는 법 (0) | 2024.05.10 |
|---|---|
| AI 데이팅 보조 앱: 어떻게 4.5개월 만에 1.5백만 다운로드를 기록했나? (0) | 2024.05.08 |
| [논문리뷰] Phi-3 Technical Report:A Highly Capable Language Model Locally on Your Phone (1) | 2024.05.06 |
| AI 사용해서 리서치 100배 빠르게 하는 법 (0) | 2024.05.06 |
| DeepL AI 번역기, 사이트 안들어가도 실행가능하다고? (0) | 2024.05.06 |



